
Build better AI through better visibility
Granica Chronicle AI is a training data visibility service which facilitates Amazon and Google data lake exploration and cost optimization, unlocking budget for reallocation to strategic AI areas such as acquiring and using more training data.
Deeply understand your data landscape
Explore your data environment with genAI-powered prompts for fast, actionable insights - no SQL required.
Optimize access and lifecycle efficiency
Identify top opportunities for compression-related savings with Granica Crunch, find and remediate costly and inefficient data lifecycle policies, and more.
Re-allocate savings to enhance AI
Use the freed up funds to improve model performance by adding and using more training data, increasing compute or other means.
Deeply and easily understand your data landscape
Explore your data environment with genAI-powered prompts that generate relevant visualizations in graphs and tables to uncover actionable insights, fast.

Explore with promptsUse natural language to ask questions of your data lake buckets and files and get answers.
Find a needle - or a whole new haystackDiscover valuable training data, understand usage and access patterns for AI applications, and more.
Uncover actionable insights, fastGet relevant visualizations in graphs and tables - no SQL, CLI, or dashboard creation required.
Data types supported
Clickstream/Logs, Tabular, LiDAR, Image, and everything in betweenGranica Chronicle AI supports any and all file types in your data lake.

Clickstream/Logs

Tabular
LiDAR
Image
Optimize inefficient data, access, and lifecycles
Maximize compression-related savings with Granica Crunch by prioritizing data lake buckets and files for crunching based on typical compression rates, historical access patterns etc. Reduce data at-rest and access costs by optimizing lifecycle tiering policies and storage classes given historical access patterns. Improve application latency and throughput while reducing access costs by identifying and remediating sub-optimal prefix/read approaches. Re-allocate the savings each month to improve model performance by adding more training data or increasing training compute.
- Gain insights into data usage for AI and ML.
- Maximize compression savings with Granica Crunch.
- Optimize tiering and storage class-related costs.
- Improve application latency and throughput.
- Re-allocate yet more savings to build better AI.
Maximize model performance with Granica Crunch insights. Where can we reallocate savings for AI/ML enhancements?
Discover training data effortlessly with genAI. How can we use it to boost our AI/ML capabilities?
Optimize AI/ML workflows with genAI. What insights can help us improve model training and overall performance?
Get started in minutes
- 1
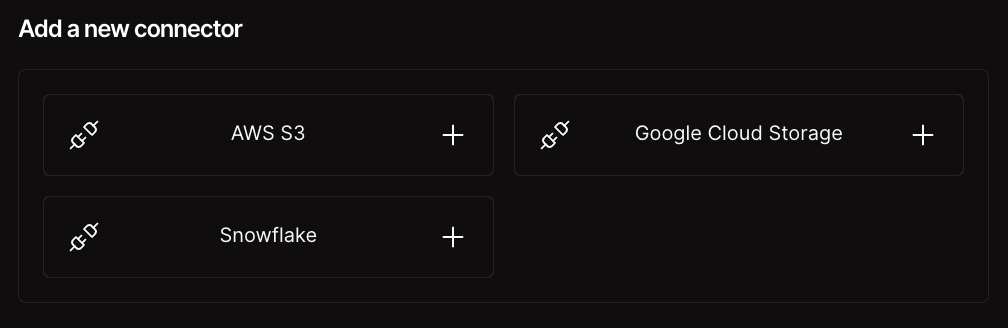
Choose your data connector
Select a pre-built connector for AWS, Google, or Snowflake. - 2
Securely share metadata
Export and securely share access logs and file metadata for Chronicle AI to ingest and query. Your actual files never leave your environment. - 3
Start chatting
Begin asking questions - and getting answers.
Frequently Asked Questions:
Ask. Get. Act.
Build better AI through (much) better visibility into how your training data is being used and how to optimize it for both cost and performance.