
Build safer, better AI by preserving data privacy
Granica Screen is a data privacy service. It helps data teams detect, classify and protect sensitive information contained within cloud data lake files - without sampling - mitigating breach risk and safely unlocking more data for use with in-house training and external generative AI services.
Elevate data security posture
Accurately classify and de-identify sensitive information and PII hidden in structured, semi-structured and unstructured text-based training files.
Cost-effectively unlock more data
Broadly apply high-efficiency, ML-powered scanning algorithms to process and safely unlock 5-10X more data vs. traditional approaches at similar cost. Stop sampling and start protecting.
Safely train on fresh data
Classify and de-identify incoming data in real-time to supply training pipelines with fresh, safe information for improved performance and accuracy.
Enhance privacy where you’re most vulnerable
Confidently handle the accelerating scale of data in your cloud data lakes to mitigate privacy, security and compliance risk while enabling teams to build better AI, faster.

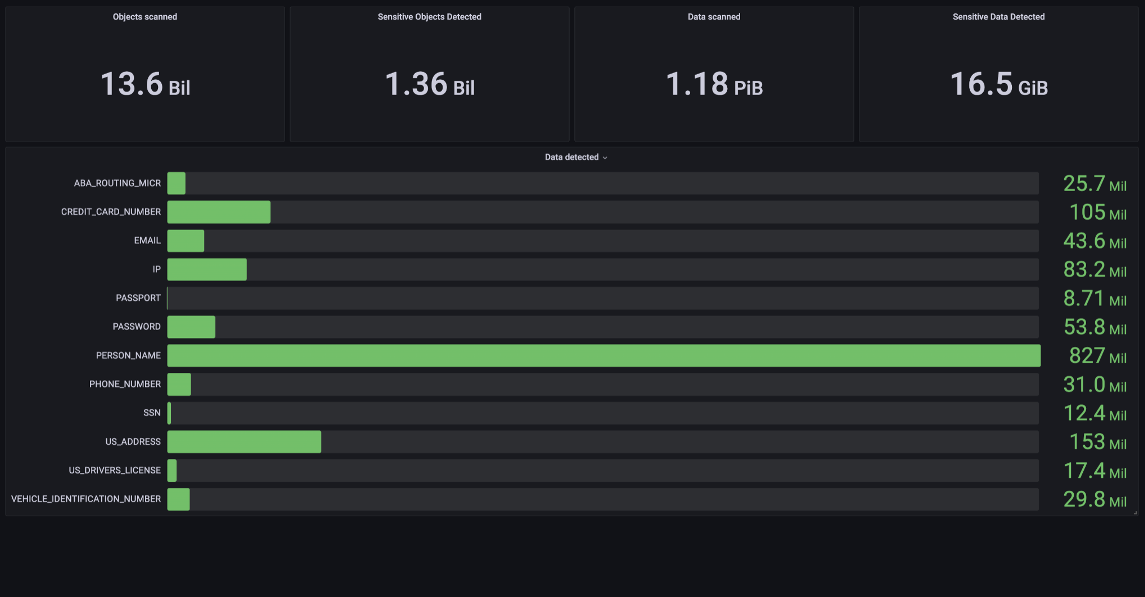
Discover & classify with leading accuracyGenerate reports for sensitive information at the field level inside files in your cloud data lake, especially data sets with high potential value for ML and AI.
Apply privacy transforms in your data pipelinesMask and de-identify at the field level inside structured, semi- and unstructured data, creating safe file copies ready for downstream processing.
Safely train on the de-identified copiesImprove model performance and accuracy with the addition of more training data and information, while maintaining data privacy and compliance.
Data types and classifiers supported
Clickstream, Logs, Tabular, and moreGranica supports a wide range of data types and classifiers (e.g. phone number, SSN, VIN etc.) for AI/ML/analytics.
Bring us your unique requirements, we can further customize for your use case.
Bring us your unique requirements, we can further customize for your use case.

Clickstream

Logs

Tabular
Cost-effectively unlock more data
Granica Screen delivers 5-10X higher compute efficiency and thus lower infrastructure cost per byte scanned vs. traditional approaches, enabling cost-effective scanning of broad data sets rather than limited sampling. Similarly, ultra-efficient masking and de-identification unlocks 5-10X more data for safe use in model training for similar total cost to alternatives. Use Screen real-time in the application write path, further mitigating breach risk and enabling immediate use for training or other needs.
- Unlock 5-10X more data to power AI/ML.
- Safely train on fresh data as it lands.
- Stay budget-neutral vs. AWS Macie and Google DLP.
Get started in minutes
- 1
Install and enable Granica Screen
Deploy into your AWS or GCP cloud environment and ensure that the Granica CLI interface is accessible. - 2
Configure data screening
Specify buckets, file types (e.g. .parquet, .csv, .json, .html, .txt, etc.), standard classifiers (e.g. Phone number, email, Social Security Number (SSN) and/or custom classifiers. - 3
Configure report output
Specify the report format (json, csv, parquet), compression, and output location in AWS S3 or GCS. Optionally, configure redaction formats for additional privacy management.
Frequently Asked Questions:
Preserve privacy. Train safely.
Unlock even more data for AI/ML teams to safely improve model performance, whether for private LLMs and generative AI, or traditional AI and machine learning.